
Los avances recientes en Al nos han animado a ser más atrevidos con la captura de documentos. En lugar de utilizar técnicas y reglas obsoletas y ajustarlas aún más, podemos dar un paso atrás y mirar la extracción de datos desde una perspectiva radicalmente nueva.


A menudo nos encontramos en conversaciones con clientes y potenciales clientes que ya están automatizando uno o varios de sus procesos documentales con documentos semi estructurados utilizando algún proveedor de sistema OCR (del inglés Optical Character Recognition). Comparten con nosotros que, ya sea en una fase de prueba de concepto o de puesta en producción, no están satisfechos con los resultados. Exploremos el por qué…
Breve Introducción a los Sistemas OCR
El reconocimiento óptico de caracteres (OCR) es el pionero del software de captura de datos de documentos. OCR tiene como objetivo leer documentos impresos y digitales, y luego organizar el texto contenido en ellos. Con la llegada de OCR llegó el comienzo de una extracción de datos de documentos más rápida y precisa.
Hay dos tipos básicos de OCR: basado en plantillas y automatizado.
El OCR basado en plantillas requiere mantenimiento manual y prevención de errores, mientras que el OCR automatizado utiliza un software más complejo para un procedimiento más automatizado.
Entonces ¿Cómo funciona exactamente un OCR? Vamos a ver.
OCR basado en plantillas
En este enfoque de captura de datos, el software OCR lee un documento y captura datos de acuerdo con reglas y plantillas predefinidas. Durante décadas, el OCR basado en plantillas estuvo a la vanguardia de la tecnología de captura de datos de documentos. Hoy en día, todavía hay muchos usos básicos para las soluciones basadas en plantillas.
Aunque las plantillas se han utilizado en la tecnología OCR desde la década de 1980, el OCR basado en plantillas ha recorrido un largo camino desde sus inicios. El OCR actual basado en plantillas puede extraer datos con un alto grado de precisión. Aún así, el OCR basado en plantillas solo funciona cuando el software lee caracteres en diseños que ha sido entrenado para comprender. Esto significa que debe configurar plantillas y reglas para cada formato del documento que desea procesar.
En el improbable caso de que todos los documentos con los que trabaja tengan exactamente el mismo diseño, esta es una solución factible. En la práctica, incluso las mejores soluciones de OCR basadas en plantillas requieren que reformatee manualmente algunos documentos.
Una vez que haya configurado todas sus reglas y plantillas, el OCR basado en plantillas requiere que verifique la precisión de cada captura. Después de la verificación manual, puede iniciar los procedimientos comerciales deseados, que pueden incluir la aprobación de pagos a proveedores, la incorporación de empleados, reclamos y pagos de seguros, declaraciones de aduana e iniciativas de CRM.
OCR cognitivo
También conocida como «software de captura de datos de documentos cognitivos», una plataforma OCR cognitiva utiliza un software innovador para comprender la información que está extrayendo. Al aplicar la tecnología de aprendizaje automático, el OCR cognitivo puede aprender a reconocer y capturar datos relevantes en una variedad de diseños de documentos a lo largo del tiempo. Esto elimina la necesidad de configurar manualmente nuevas plantillas.
Sin necesidad de volver a formatear manualmente, el OCR cognitivo le permite automatizar completamente la entrada de datos. En teoría, incluso puede llegar a crear un procesamiento de documentos completamente sin contacto, si su empresa se siente cómoda con que el software maneje operaciones como aprobaciones. En la práctica, siempre es una buena idea mantener a un humano informado para monitorear la precisión.
Si bien una solución de captura de datos automatizada puede parecer una mejora obvia para la mayoría de las funciones comerciales, algunas personas aún no confían en ese nivel de automatización. Los responsables de la toma de decisiones en su organización pueden desconfiar un poco de la adopción de tecnologías como la inteligencia artificial (IA) y el aprendizaje automático, o el procesamiento de documentos que opera desde la nube. Aunque el OCR cognitivo tiene una montaña de beneficios, es posible que deba hacer un esfuerzo adicional para explicar las ventajas del OCR cognitivo antes de que todos estén a bordo.
Datos estructurados vs. datos semiestructurados
El procesamiento inteligente de documentos tiene como objetivo crear datos estructurados a partir de documentos no estructurados y semiestructurados. Comprender estos tipos de datos es fundamental para comprender cómo funciona el procesamiento inteligente de documentos.
Los documentos estructurados son idénticos en términos de tamaño y apariencia, con información categorizada, etiquetada y ubicada claramente. El ejemplo clásico de datos estructurados es una prueba de opción múltiple que tiene campos idénticos. Un procesador de documentos básico puede leer documentos estructurados con OCR basado en plantillas.
Sin embargo, la mayoría de los documentos no están tan estructurados como nos gustaría. Muchos documentos comerciales están semiestructurados, lo que significa que tienen la misma estructura básica pero pueden tener diferentes diseños y contenido. Algunas contienen ciertas constantes; por ejemplo, todas las facturas incluyen la fecha, el nombre del proveedor y el monto total adeudado. Pero las facturas también incluyen variables, como partidas, descuentos o penalizaciones. La ubicación de cada campo de encabezado también puede diferir de una factura a otra. En este caso, una solución de OCR basada en plantillas requeriría un reformateo manual. Sin embargo, una plataforma de escaneo OCR cognitivo puede procesar documentos semiestructurados y usar el aprendizaje automático para mejorar con el uso continuo.
Los documentos variables complican las cosas
Desafortunadamente, el enfoque tradicional de OCR falla gravemente una vez que la variabilidad del documento se convierte en un factor. Es probable que descubra que tiene que rehacer todo el trabajo necesario para reconocer un tipo específico de documento, incluso con un formato ligeramente alterado. Dado que los documentos se modifican periódicamente en todas las industrias, la variabilidad de los documentos es un problema bastante común.
Puede configurar el reconocimiento para cada formato de factura, un enfoque que requiere mucho tiempo y que muchos han probado. Pero tan pronto como se dé cuenta de lo variables que pueden ser los documentos, verá lo ineficaz que puede ser el reformateo manual.
Usemos las facturas como ejemplo. Si está trabajando con 60 proveedores en diez países diferentes, eso significa hasta 60 formatos de factura distintos, cualquiera de los cuales puede cambiar en cualquier momento. Además, diez países diferentes significan que existen potencialmente diez estándares legales diferentes que las oficinas de contabilidad de cada empresa deben cumplir. Además de eso, cada uno de sus 60 proveedores tiene sus propios requisitos internos para los tipos de datos que deben incluir las facturas.
Con una clientela global, es muy posible que sus facturas utilicen más de un idioma. El OCR tradicional requiere una solución que reconozca cada idioma con un conjunto de reglas basadas en texto. Además, si está utilizando plantillas basadas en imágenes, deberá asegurarse de que cada factura que envíe un proveedor no esté rotada o borrosa, y use exactamente el mismo formato que el que diseñó para que lea su sistema.
Pero espera hay mas. El OCR tradicional también le causará dolores de cabeza cada vez que haya una factura que contenga anotaciones inusuales o elementos de línea que su sistema no esté preparado para manejar. Tenga en cuenta que esto está sucediendo con 60 proveedores diferentes al mismo tiempo.
A estas alturas, probablemente sea dolorosamente consciente de los costes y las complicaciones de una solución de OCR tradicional cuando se trata de documentos variables. Al igual que muchas empresas, es posible que decida volver a la entrada manual.

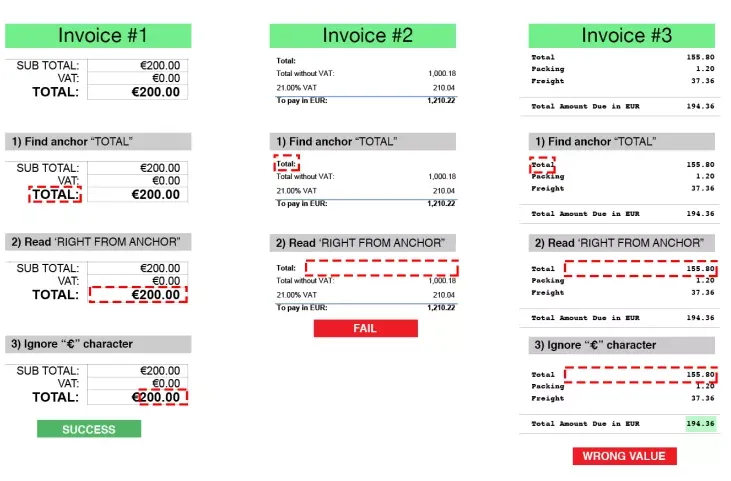
Como puede ver, además de cubrir todas las diferentes frases, el problema menos obvio es la posibilidad de falsos positivos. Son reglas demasiado universales, lo que te llevaría a capturar datos erróneos. Los subtotales se convierten en totales. El envío se convierte en IVA. Los falsos positivos están en todas partes.
En última instancia, el OCR tradicional obliga a crear reglas basadas en texto para cada proveedor, un proceso conocido como «huella digital». Pero la toma de huellas dactilares no es tan de alta tecnología como puede parecer. Las reglas basadas en texto son tan sensibles al proceso de escaneo como las plantillas basadas en imágenes. OCR se desarrolló originalmente para digitalizar libros y periódicos: aplicar la misma tecnología a los documentos comerciales puede generar errores rápidamente. Al leer documentos con un diseño complicado, el sistema puede tener dificultades para detectar todas las cadenas de texto en una página. En el momento en que aparece un pequeño problema, como una fuente demasiado pequeña, una mancha o un sello que cubre parte del texto, su plantilla desaparece.
Con las reglas basadas en texto, algunas plantillas de OCR inicialmente le dan la ilusión de flexibilidad: simplemente vincula un tipo de campo de datos a las frases obvias de la etiqueta. La popularidad del OCR basado en texto ha hecho que muchas empresas crean que esta es la captura de documentos más avanzada que jamás obtendrán.
Una vez más, utilizando las facturas como nuestros documentos de ejemplo, observe las imágenes de muestra a continuación y tómese un par de minutos para tratar de elaborar algunas buenas reglas flexibles para los campos de datos.
El OCR tradicional también comete errores letra por letra, especialmente en un entorno desconocido. Eso significa que si una «S» en un poema se ve un poco manchada, el OCR podría corregirla a un signo de dólar ($). Pero no hay muchas cantidades de dólares en poesía… Las soluciones tradicionales de OCR no saben cuándo se equivocan, en otras palabras, no funcionan de manera inteligente.
El Futuro
Los avances recientes en Al nos han animado a ser más atrevidos con la captura de documentos. En lugar de utilizar técnicas y reglas obsoletas y ajustarlas aún más, podemos dar un paso atrás y mirar la extracción de datos desde una perspectiva radicalmente nueva.
Nos preguntamos: ¿por qué los ordenadores son tan malos en esto, cuando los humanos pueden hacerlo realmente bien?
El sistema de Automatización Inteligente TAAD se Serimag proporciona;
En Serimag llevamos más de 10 años desarrollando proyectos de Tratamiento Automático de Documentos para el sector bancario con clientes como Caixabank, Santander o BBVA. Procesamos más de un millón de páginas al día, extrayendo más de 400 tipos de datos de más de 50 tipos documentales en más de 80 procesos bancarios diferentes.
En un modelo de pago éxito, ayudamos a nuestros clientes a generar ahorros a través de la automatización, transformando sus procesos para reducir tiempos, errores y permitir una mayor escalabilidad.


