
Recent advances in Al have encouraged us to be more daring with document capture. Instead of using outdated techniques and rules and tweaking them further, we can take a step back and look at data mining from a radically new perspective.


We often find ourselves in conversations with clients and potential clients who are already automating one or more of their document processes with semi-structured documents using an OCR ( Optical Character Recognition) system provider. They share with us that, whether in a proof-of-concept or production start-up phase, they are not satisfied with the results. Let’s explore why…
Brief Introduction to OCR Systems
Optical Character Recognition (OCR) is the pioneer of document data capture software. OCR aims to read printed and digital documents, and then organize the text contained in them. With the advent of OCR came the beginning of faster and more accurate document data extraction.
There are two basic types of OCR: template-based and automated.
Template-based OCR requires manual maintenance and error prevention, while automated OCR uses more complex software for a more automated procedure.
So how exactly does an OCR work? Let’s see.
Template-based OCR
In this data capture approach, the OCR software reads a document and captures data according to predefined rules and templates. For decades, template-based OCR was at the forefront of document data capture technology. Today, there are still many basic uses for template-based solutions.
Although templates have been used in OCR technology since the 1980s, template-based OCR has come a long way since its inception. Today’s template-based OCR can extract data with a high degree of accuracy. Even so, template-based OCR only works when the software reads characters in layouts that it has been trained to understand. This means that you must set up templates and rules for each document format you want to process.
In the unlikely event that all the documents you work with have exactly the same layout, this is a workable solution. In practice, even the best template-based OCR solutions require you to manually reformat some documents.
Once you have set up all your rules and templates, template-based OCR requires you to verify the accuracy of each capture. After manual verification, you can initiate the desired business procedures, which may include approval of vendor payments, employee onboarding, insurance claims and payments, customs declarations and CRM initiatives.
Cognitive OCR
Also known as “cognitive document data capture software,” a cognitive OCR platform uses innovative software to understand the information it is extracting. By applying machine learning technology, cognitive OCR can learn to recognize and capture relevant data in a variety of document layouts over time. This eliminates the need to manually configure new templates.
Without the need for manual reformatting, cognitive OCR allows you to fully automate data entry. In theory, you can even go so far as to create completely touchless document processing, if your company is comfortable with the software handling operations such as approvals. In practice, it is always a good idea to keep a human informed to monitor accuracy.
While an automated data capture solution may seem like an obvious improvement for most business functions, some people still don’t trust that level of automation. Decision makers in your organization may be a bit wary of adopting technologies such as artificial intelligence (AI) and machine learning, or document processing that operates from the cloud. While cognitive OCR has a mountain of benefits, you may need to go the extra mile to explain the advantages of cognitive OCR before everyone is on board.
Structured vs. semi-structured data
Intelligent document processing aims to create structured data from unstructured and semi-structured documents. Understanding these types of data is critical to understanding how intelligent document processing works.
Structured documents are identical in terms of size and appearance, with information categorized, labeled and clearly located. The classic example of structured data is a multiple choice test that has identical fields. A basic document processor can read structured documents with template-based OCR.
However, most documents are not as structured as we would like them to be. Many business documents are semi-structured, meaning that they have the same basic structure but may have different layouts and content. Some contain certain constants; for example, all invoices include the date, the name of the supplier and the total amount due. But invoices also include variables, such as line items, discounts or penalties. The location of each header field may also differ from invoice to invoice. In this case, a template-based OCR solution would require manual reformatting. However, a cognitive OCR scanning platform can process semi-structured documents and use machine learning to improve with continued use.
Variable documents complicate matters
Unfortunately, the traditional OCR approach fails badly once document variability becomes a factor. You may find that you have to redo all the work necessary to recognize a specific type of document, even with slightly altered formatting. Since documents are changed periodically in all industries, document variability is a fairly common problem.
You can set up recognition for each invoice format, a time-consuming approach that many have tried. But as soon as you realize how variable documents can be, you will see how ineffective manual reformatting can be.
Let’s use invoices as an example. If you are working with 60 suppliers in ten different countries, that means up to 60 different invoice formats, any of which you can change at any time. In addition, ten different countries means that there are potentially ten different legal standards that each company’s accounting office must comply with. In addition to that, each of its 60 suppliers has its own internal requirements for the types of data that invoices must include.
With a global clientele, your invoices are likely to use more than one language. Traditional OCR requires a solution that recognizes each language with a set of text-based rules. In addition, if you are using image-based templates, you will need to make sure that each invoice a vendor sends is not rotated or blurred, and uses exactly the same format as the one you designed your system to read.
But wait, there’s more. Traditional OCR will also cause you headaches every time there is an invoice containing unusual annotations or line items that your system is not equipped to handle. Note that this is happening with 60 different suppliers at the same time.
By now, you are probably painfully aware of the costs and complications of a traditional OCR solution when dealing with variable documents. Like many companies, you may decide to revert to manual entry.

As you can see, in addition to covering all the different phrases, the less obvious problem is the possibility of false positives. These are too universal rules, which would lead you to capture erroneous data. Subtotals are converted to totals. Shipping is converted to VAT. False positives are everywhere.
Ultimately, traditional OCR forces the creation of text-based rules for each supplier, a process known as “fingerprinting”. But fingerprinting is not as high-tech as it may seem. Text-based rules are as sensitive to the scanning process as image-based templates. OCR was originally developed to digitize books and newspapers: applying the same technology to business documents can quickly generate errors. When reading documents with a complicated layout, the system may have difficulty detecting all text strings on a page. The moment a small problem appears, such as a font that is too small, a smudge or a stamp covering part of the text, your template disappears.
With text-based rules, some OCR templates initially give you the illusion of flexibility: simply link a data field type to the obvious tag phrases. The popularity of text-based OCR has led many companies to believe that this is the most advanced document capture they will ever get.
Again, using invoices as our example documents, look at the sample images below and take a couple of minutes to try to work out some good flexible rules for the data fields.
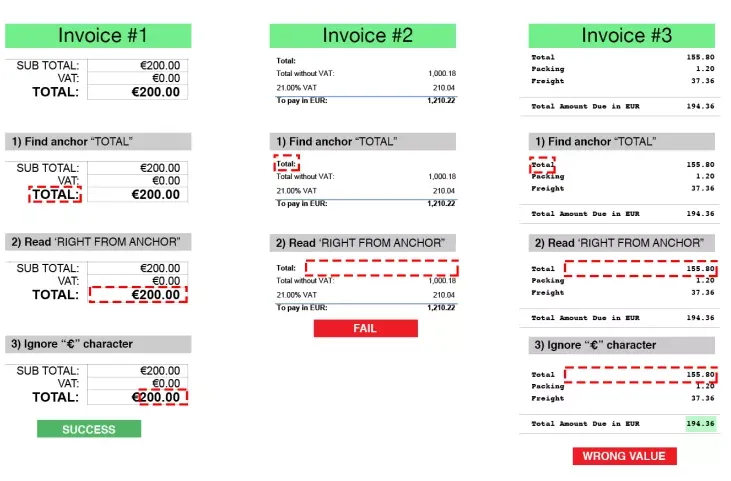
Traditional OCR also makes letter-by-letter errors, especially in an unfamiliar environment. That means that if an “S” in a poem looks a little smudged, OCR could correct it to a dollar sign ($). But there aren’t a lot of dollar amounts in poetry…. Traditional OCR solutions do not know when they are wrong, in other words, they do not work intelligently.
The Future
Recent advances in Al have encouraged us to be more daring with document capture. Instead of using outdated techniques and rules and tweaking them further, we can take a step back and look at data mining from a radically new perspective.
We ask ourselves: why are computers so bad at this, when humans can do it really well?
Serimag’s TAAD Intelligent Automation System provides;
In Serimag we have been developing Automatic Document Processing projects for the banking sector for more than 10 years with clients such as Caixabank, Santander or BBVA. We process more than one million pages per day, extracting more than 400 types of data from more than 50 document types in more than 80 different banking processes.
In a successful payment model, we help our clients generate savings through automation, transforming their processes to reduce time, errors and enable greater scalability.